
Die Zukunft. Cyberdyne Systems, ein Unternehmen das künstliche Intelligenz auf Basis von neuronalen Netzen für das Militär erforscht, entwickelt den neuralen Netz-Prozessor (Neural Net CPU) – eine selbst lernende CPU – die Basis der künstlichen Intelligenz „Skynet“ ist.
Skynet generiert einen sich schnell anpassenden Virus der die vernetzten Rechner des Landes lahmlegt und das Militär zur Entscheidung veranlasst, Skynet scharf zu schalten. Skynet erhält Zugriff auf das Militärnetzwerk, infiltriert es, und übernimmt die Kontrolle über die US-Militärressourcen und greift Russland mit nuklearen Langstreckenraketen an, um einen nuklearen Gegenschlag zu provozieren, was auch gelingt.
Der Tag des Jüngsten Gerichts. Auf den Erst- und Gegenschlag folgt ein nuklearer Winter. Viele Überlebende, die den Atomschlag überstanden haben sterben an Hunger, Krankheiten und Versorgungsnotständen.

So hat sich James Cameron im Science-Fiction-Film Terminator aus dem Jahr 1984 die Zukunft vorgestellt.
Er sollte sich irren. Am 25. Juli 2004, dem Tag des Jüngsten Gerichts, hat sich die Koalition über ein neues Energierecht geeinigt, ist die russische Stabhochspringerin Jelena Isinbajewa Weltrekord gesprungen und ein Personenzug ist in der türkischen Provinz Aydin im Westen des Landes mit einem Bus zusammengestoßen bei dem 14 Tote zu beklagen waren. Aber sonst ist nichts Weltbewegendes geschehen.
Ich bin in den 80zigern aufgewachsen. Heimcomputer und Science-Fiction faszinieren mich bis heute. Eigentlich alles was mit Technik, Weltraum und Zukunft zu tun hat. 1984 war ein ganz besonderes Jahr. Ich kaufte meinen C64 und etwas später mit meinem Bruder die 1541. Ein Stück Zukunft für zuhause; schön verpackt in einem freundlichen Brotkasten.
Und natürlich habe ich wie jeder Junge gerne Science-Fiction-Filme geschaut. An viele Filme kann ich mich gut erinnern: Aliens, Blade Runner, Zurück in die Zukunft. Viele Filme habe ich aber auch wieder vergessen. Aber einer sticht ganz besonders heraus und nimmt bis heute einen ganz besonderen Platz unter meiner Gehirnrinde ein: Terminator.
Für mich eine Glanzleistung in erzählerischer Intensität und inszenatorischem Geschick. Die Art und Weise, wie in Terminator die Geschichte erzählt wird, erinnert mich an das Kultspiel Half-Life 2. Terminator erzählt die Geschichte quasi mitten im Geschehen, ohne die Handlung zu unterbrechen oder die Spannung auch nur in einer Sekunde aufzugeben. Der Terminator hat nicht nur Sarah Connor und Kyle Reese unerbittlich vor sich her getrieben, sondern auch die Handlung und die Zuschauer. Eiskalt, berechnend, gnadenlos.
Ich war 15 als ich den Film auf einer VHS-Kopie gesehen habe und muss gestehen: Ich war völlig weggeblasen. Wuchtiges, packendes Action-Kino, wie auch seine Fortsetzung: Terminator 2. Danach war die Luft raus. Die Fortsetzungen haben das Niveau der ersten beiden Teile nicht annährend erreichen können, trotz dem vielfachem an Budget.
Alles nur Spinnerei
Die Gamestar zählt Terminator zu Hollywoods verfehlten Zukunftsvisionen. Ist dem so?
Wie stellt sich Cameron denn im Film Terminator die Zukunft vor?
- Zeitreisen
- weltweit vernetzte Computer
- Künstliche Intelligenz Skynet
Ja gut, Zeitreisen sind nicht möglich. Aber das kann man Cameron nicht anlasten. Denn der Flux-Kompensator kam mit BTTF ja erst ein Jahr später in die Kinos.
Wie sieht es mit den global vernetzen Computern aus? Als der Terminator 1984 in die Kinos kam, gab es kein World-Wide-Web und auch kein Internet. Vernetzte Rechner waren eigentlich nur an Universitäten und beim Militär zu finden. Es ist darüber hinaus erstaunlich, wie Cameron die Gefahren, die von vernetzten Systemen ausgehen können, erschreckend präzise vorhergesagt hat.
Und was hat es mit der KI auf sich? Im Film entwickelt Cyberdyne Systems eine selbstlernende CPU auf Basis neuronaler Netze (Neural Net CPU). Auch eine verfehlte Zukunftsvision Hollywoods?

Die Gegenwart, DeepMind entwickelt einen selbstlernenden Algorithmus auf Basis neuronaler Netze
Im Januar 2016 wurde die Go-Welt von einer Nachricht erschüttert. Das Londoner Softwarehaus DeepMind hatte ihr Programm AlphaGo bereits im Oktober 2015 in einem geheimen Match gegen den amtierenden Europameister Fan Hui antreten lassen und diesen mit 5:0 bezwungen.

Das kam für die Go-Welt wie ein Blitz aus heiterem Himmel. Plötzlich, überraschend und völlig unvorbereitet. Denn – anders als beim Schach – hatten Go-Engines bis zu diesem Zeitpunkt nicht den Hauch einer Chance gegen professionelle Go-Spieler. Das Spiel galt als zu komplex, zu tief, zu schwierig zu bewerten für Computer-Programme. Die besten Go-Programme waren so schlecht, dass Go-Profis mit Handicap gespielt haben, und Computern vier bis fünf Züge Vorsprung gaben.
Go hat in Asien einen so hohen Stellenwert, dass es in China, Südkorea und Japan Nationalsport ist. In China ist es sogar ein reguläres Schulfach. Wer das Spiel beherrscht, trifft sein Leben lang die richtigen Entscheidungen, behaupten seine Anhänger – und lassen deshalb schon die Kleinen täglich trainieren. Über 2.000 professionelle Spieler verdienen mit Go ihren Lebensunterhalt.
Die Go-Szene gab sich daher nicht so schnell geschlagen. Zunächst wiesen Go-Experten darauf hin, dass Hui Fan zwar Europameister, aber nur Rang 500 der Weltrangliste einnehme und damit kein Maßstab sei. Im März 2016 trat AlphaGo alsdann gegen den besten Spieler der letzten Dekade an; dem ehemaligen Go-Weltmeister, Träger von 18 internationalen Titel und Nr. 4 der Weltrangliste Lee Sedol aus Südkorea.
Das Duell war in Asien ein Megaereignis. Jede Partie wurde live im TV übertragen. 280 Millionen Zuschauer haben die Partien verfolgt. 35.000 Artikel sind in der Presse dazu erschienen. Go-Bretter waren ausverkauft; der Umsatz hat sich verzehnfacht. Nach der ersten verlorenen Partie war Sedol, die versammelte Presse und die Kommentatoren sichtlich geschockt.
Lee Sedol ist eine lebende Legende. Vor dem Event hat er erklärt, er werde 5:0 gewinnen. Er unterlag mit 4:1.
Nach der dritten verlorenen Partie erklärte er, er sei vom Spiel des Computers schockiert und habe sich nach den ersten beiden verlorenen Spielen stark unter Druck gefühlt. Immerhin konnte Sedol die vierte Partie für sich entscheiden. Demis Hassabis, Gründer und CEO von DeepMind, erklärte später Sedol´s 78. Zug sei unglaublich gewesen. So brillant, dass AlphaGo nicht damit gerechnet habe.
Das lag daran, so Hassabis, dass AlphaGo mit tausenden Meister- und Amateurpartien gefüttert worden ist und über zwei neurale Netzwerke und eine Monte-Carlo Tree-Search-Methode, diejenigen Züge ausgewählt habe, die denen des Menschen am ähnlichsten seien. So gute Züge spielen Menschen normal nicht, so Hassabis. Später habe man sich die Logbücher angesehen, und festgestellt, dass die Wahrscheinlichkeit dass ein Profi diesen Zug spielt 0,007% beträgt (etwa 1 zu 10.000).
Kleiner Trost für Lee Sedol: Seine eine Siegpartie sollte die letzte eines Menschen gegen AlphaGo bleiben, denn der Siegeszug von AlphaGo ging weiter.
Zum Jahreswechsel 2016/17 spielte eine anonyme AphaGo-Version (AlphaGo Master) im Internet gegen quasi alle Top-Profis der Welt und gewann 60:0. Die Partien sind hier.
Tobias Berben, Deutscher Blitz-Go-Meister und verantwortlicher Redakteur der Deutschen Go-Zeitung schrieb dazu: „Insgesamt hat das Programm 30 Partien auf dem koreanischen Tygem-Server und 30 Partien auf dem chinesischen Fox-Server gegen praktisch die gesamte Profi-Elite beider Länder gespielt und dabei den unglaublichen Score von 60:0 errungen. Und wenn man die Partien nachspielt, möchte man hinzufügen: Es wirkte spielerisch und ungefährdet wie das Go von einem anderen Planeten!“
Alle Hoffnungen lagen nun beim chinesischen Star und Weltranglistenersten Ke Jie, die Ehre der Go-Spieler zu retten. Vergebens. Im Mai 2017 unterlag Ke Jie gegen eine abermals verbesserte Version von AlphaGo mit 3:0. Die letzte menschliche Bastion war durch einen Computer besiegt worden. Für die Go-Welt eine Zäsur.

Doch es sollte noch schlimmer kommen: Im Oktober 2017 publizierten die Entwickler von AlphaGo die Ergebnisse der jüngsten Entwicklungsstufe: AlphaGo Zero. Diese Version läuft mit deutlich reduzierter Hardware-Architektur und mit keinerlei Vorwissen über das Spiel, sondern ist ausschließlich mit den Spielregeln ausgestattet und durch Spiele gegen sich selbst trainiert worden. Nach 72 Stunden war es bereits so gut, dass es gegen die AlphaGo-Version, die im Mai 2017 noch die Nr. 1 der Welt besiegt hatte, mit 100:0 schlug.
WER IST DEEPMIND?
DeepMind ist ein britisches Start-up, gegründet 2010 von Demis Hassabis, Shane Legg und Mustafa Suleymandas , das sich auf die Programmierung von Künstlicher Intelligenz (KI) spezialisiert hat. 2014 2014 wurde es von Google übernommen. Mehrere Milliardäre haben in DeepMind investiert, darunter Elon Musk (Tesla Motors), Paypal-Gründer und ursprünglicher Facebook-Geldgeber Peter Thiel, der Skype-Mitgründer Jaan Tallinn sowie der Hongkonger Magnat Li Ka-shing, einer der mächtigsten Männer Asiens.
Bei DeepMind dreht sich alles darum, eine KI mit dem menschlichen Gehirn als Blaupause zu bauen.

Ja, es ist sehr beeindruckend, dass das Computerprogramm AlphaGo besser spielen kann, als jeder Mensch. Gerade vor dem Hintergrund, dass Go um ein vielfaches komplexer ist als Schach und für Maschinen als unknackbar galt.
Erst kurz bevor Alpha Go die komplette Großmeister-Elite im Go vernichtend geschlagen hatte, titelte das Magazin WIRED „The Mystery of Go, the Ancient Game That Computers Still Can’t Win“ und legte darin die Gründe dar, warum Go-Programme an menschlichen Spielern scheitern.
Viel beeindruckender ist aber das WIE! DeepMind hat mit der neuen Version, AlphaZero, einen generischen, selbstlernenden Algorithmus erschaffen, der sich die Grundlagen, Strategien und Taktiken durch das bloße Spielen gegen sich selbst beigebracht hat. Ganz allein, ohne menschlichen Input. Ohne jedes Vorwissen, bei Null sozusagen. Während die Vorgänger-Version mit zigtausend menschlichen Partien gefüttert worden ist, kennt AlphaZero nichts weiter als die Regeln.
AlphaZero hat Wissen aus dem Nichts geschaffen. Außerirdisch. Dabei hat es für den Menschen nicht zu erschließende Taktiken und Strategien gefunden. Und das ist nicht alles.
Die neue Version ist nicht auf ein Spiel beschränkt. Sie ist generisch, was bedeutet, dass diese Alpha-Version auch auf andere Anwendungen übertragbar ist. So hat AlphaZero das stärkste Shōgi-Programm names Elmo mit 90:8 geschlagen, nachdem es sich das Spiel durch selbständiges Training in zwei Stunden selbst beigebracht hat.
Nochmal: Durch selbstlernendes Spielen gegen sich selbst. Apropos, da war doch was. Kennt Ihr noch?

Ist lange her. 1983. Und … ? Klar, War Games. Das hier ist eine Schlüssel-Szene. Der Super-Computer WOPR (War Operation Plan Response) wird gebeten, gegen sich selbst zu trainieren, um das Konzept eines nicht gewinnbaren Spiels zu verstehen. Der Teenager David L. Lightman, gespielt von Mathew Broderick, fragt in dieser Szene: “Is there any way that it can play itself?”
Es gelingt David, WOPR die Sinnlosigkeit eines nuklearen Kriegs beizubringen, indem er den Computer Tic-Tac-Toe gegen sich selbst spielen lässt. WOPR lernt dabei, dass keiner gewinnen kann, und probiert daraufhin alle Atomkriegsstrategien aus, von denen ebenfalls keine siegreich wäre.
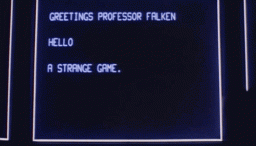
Nach dem Durchlaufen aller Simulationen des Kriegsverlaufes erklärt WOPR: „Ein seltsames Spiel. Der einzig gewinnbringende Zug ist, nicht zu spielen.“
Daraufhin beendet WOPR das Spiel und damit auch die realen Abschussvorbereitungen in letzter Sekunde. Ob AlphaZero genauso gehandelt hätte?
Google DeepMind hat nach dem Sieg gegen den Go-Großmeister Ke Jie erklärt, ihr Programm an keinen Go-Turnieren mehr antreten zu lassen. Go ist also für DeepMind erledigt. Die Go-Welt liegt ja ohnehin bereits am Boden. Aber so ist es gar nicht. Für die Go-Szene ist AlphaGo ein Geschenk, vom dem sie lernen können und das sie von alten Denkmustern befreit hat. So sehen es die Profis. Für Ke Jie ist ist AlphaGo ein Gott.
So fing alles an. Deep Q-Learning: Mit Atari´s Breakout zu Künstliche Intelligenz
Wie war das alles möglich?
Die überraschende Antwort: Durch Videospiele!
Ja, richtig gelesen! Aber nicht irgendwelche Videospiele, sondern die Atari 2600-Klassiker Pong, Breakout, Space Invaders, Seaquest, Beam Rider, Enduro und Q*Bert.

Im Dezember 2013 hat DeepMind mit dem Papier „Playing Atari with Deep Reinforcement Learning“ ihre Forschungsergebnisse zum „maschinellen Lernen“ vorgestellt.
Deep Q-network (DQN) nennt DeepMind seinen Allzweckagenten. Das neurale Netzwerk spielt klassische Atari-Games ohne Vorwissen. Es kennt keine Regeln des Spiels, keine Spielmechaniken und versteht auch nichts von Ballistik. Agent lernt ausschließlich durch den Input aus dem Videoeingang (RAW Pixel) und der Interaktion mittels der Joystickbewegungen das Spiel zu verstehen. Learning by Doing. Oder, wie dieser Bereich des maschinellen Lernens im Fachjargon heißt: Reinforcement Learning. Es sieht quasi nur die Pixel und den Punktestand. Try an Error. DQN weiß nur, dass viele Punkte gut sind und wenig Punkte schlecht. Das Atari 2600 hat eine Auflösung von 210 x 160 Pixel, also eine überschaubare Anzahl von Pixel, die Agent verarbeiten muss.
Our goal is to create a single neural network agent that is able to successfully learn to play as many of the games as possible.
DeepMind
Wenn DQN zu spielen beginnt, beobachtet er einfach die Frames des Spiels und macht zufällige Tastenbetätigungen, um zu sehen, was passiert. „Ein bisschen wie ein Baby, das seine Augen öffnet und die Welt zum ersten Mal sieht“ meint Hassabis, Gründer und CEO von DeepMind.
Erst muss Deep Mind aber verstehen, was auf dem Bildschirm passiert. Es muss zunächst u.a. die Sprites identifizieren und wie sie miteinander interagieren. Das ist für uns Menschen keine Denkarbeit, die KI benutzt hierfür Algorithmen, wie z.B. Kantenerkennung, die auch Robotersysteme in modernen Fabriken verwenden.
Erst jetzt beginnt die eigentliche „Lernarbeit“. DQN verwendet wie der Name vermuten lässt ein neuronales Netz, das um eine Speicherkomponente erweitert wurde, weshalb Deep Mind ihre KI gerne auch als neuronale Turing Maschine bezeichnen.
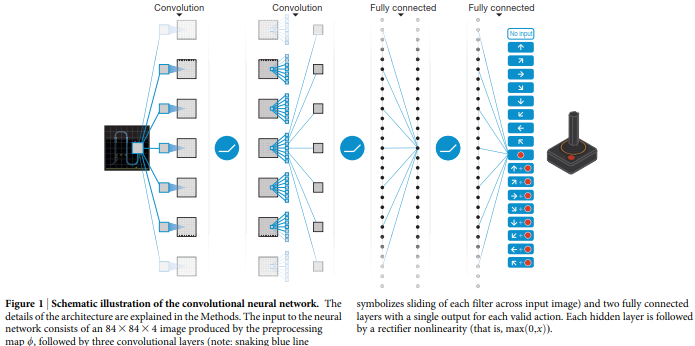
Die Ergebnisse sind beeindruckend. DeepMind hat neben ihren Forschungsergebnissen auch eine Reihe von Videos Online gestellt. Um es vorwegzunehmen: DeepMind´s DQN gelang es, sowohl die Spielregeln zu erlernen als auch Erfolgstaktiken selbstständig zu entwickeln. DQN zeigt am Anfang meist zufällige und weitgehend erfolglose Bewegungen, aber nach etlichen Durchläufen und vielen Stunden intensiven Gamings hat er herausgefunden, worum es bei den meisten Spielen geht.
Ich hab´s ja schon immer geahnt, Videospiele machen schlau!
So auch bei Breakout. Das Video zeigt die Verbesserung im Zeitablauf bzw. nach jeweils 200 Durchläufen. Nach zwei Stunden spielt DQN bereits wie ein Experte – besser als jeder Mensch. Aber nach vier Stunden bzw. 600 Durchläufen passiert etwas Erstaunliches. DQN hat die optimale Strategie gefunden und schießt einen Tunnel durch die Wand, um den Ball über die Wand zu befördern und so das Spiel zu gewinnen.
Der Punktestand wird oben links auf dem Bildschirm angezeigt (maximal sind 448 Punkte drin), die Anzahl der verbleibenden Leben steht in der Mitte (beginnend mit 5 Leben), und die „1“ oben rechts zeigt an, dass es ein Solospiel ist.
Tim Behrens, Professor für kognitive Neurowissenschaften an der University College London zeigte sich beeindruckt: „Was sie da gemacht haben, ist wirklich beeindruckend, gar keine Frage. Ihr Agent lernt Konzepte, die auf Belohnungen und Bestrafungen basieren. Das hat noch niemand zuvor gemacht. „
Nicht alle Spiele liegen DQN.
In Seaquest ist der Agent nicht ganz so gut. Menschen können das besser. Das liegt womöglich daran, dass man bei Seaquest regelmäßig zur Oberfläche auftauchen muss, um den Sauerstofftank aufzufüllen. Die Sauerstoffanzeige wird am unteren Bildschirmrand angezeigt. Damit das neurale Netz das versteht, braucht es wohl etliche (Tausende?) Tauchgänge äh Durchläufe. Und dennoch ist die Lernfunktion erstaunlich.

Die Abbildung zeigt die Visualisierung der Lern-Wertfunktion des Agenten am Beispiel von Seaquest. A, B und C rechts im Bild sind Screenshots aus dem Spiel. (A) Nachdem ein Feind auf der linken Bildschirmseite erscheint, steigt der Lernwert. Agent feuert einen Torpedo auf den Gegner und der Wert steigt weiter, während der Torpedo auf den Gegner trifft (B). Nachdem der Feind verschwunden ist, sinkt der Wert (C).
Wie ist das Ergebnis bei den sieben Klassikern nun insgesamt ausgefallen? Bei Breakout, Space Invaders, Enduro und Pong erzielte DQN mehr Punkte als erfahrene menschliche Spieler, bei Beam Rider etwa genauso viele. Bei Q*bert, und Seaquest war DQN allerdings weit von menschlichen Leistungen entfernt. Diese Spiele sind lt. DeepMind herausfordernder, weil sie das Netzwerk dazu zwingen eine Strategie zu finden, die sich über viele Durchläufe und lange Zeiträume erstreckt.
Bei den sieben Atari-Klassikern ist es aber nicht geblieben. Offenbar hat DQN an Videospielen Gefallen gefunden. Ich kann´s verstehen. Am 26. Februar 2015 wurde im Magazin nature eine weitere Dokumentation über „deep reinforcement learning“ veröffentlicht. Deep Mind hat seinem spielsüchtigen KI-Agenten – neben den sieben bekannten Titeln – 42 weitere Spiele vorgesetzt. Darunter auch solche Perlen wie H.E.R.O. und River Raid von Activison oder Zaxxon von Sega. Na, da hat DQN aber mal richtig gut aufgepasst.

Diesmal scheint sich DQN die Spiele selbst ausgesucht zu haben. Womöglich hatte er Zugriff auf GoG.com und hat die Bewertungen gelesen. Das hat DeepMind schon clever gemacht. Eine spielende KI ist mir ja richtig symphytisch. Und dazu noch alte Klassiker von Atari & Co.
In der folgenden Tabelle sind alle 49 Spiele sowie die Resultate von DQN aufgelistet.
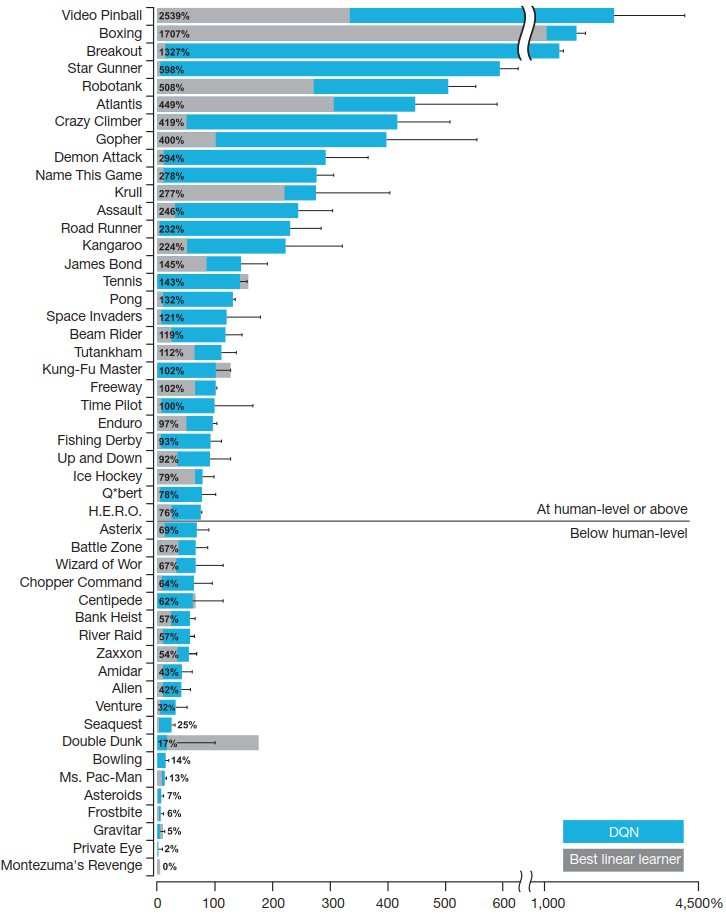
Viele Spiele beherrscht DQN wirklich gut. Die meisten besser, als jeder Hardcore-Gamer. Aber an Montezuma’s Revenge ist er kläglich gescheitert.

Warum sich DQN mit Montezuma’s Revenge so schwer tut, hat DeepMind nicht weiter erklärt. Das muss es auch nicht. Es reicht aus, sich den obigen Screenshot in aller Ruhe anzusehen. Montezuma’s Revenge ist für DQN schwer zu entschlüsseln, denn es enthält ein Rätsel. Menschen erkennen sofort den Schlüssel und assoziieren damit „Schlüssel öffnen Türen“. Für Menschen erschließt sich die Lösung damit sofort. DQN hat keine Ahnung was ein Schlüssel ist und es kennt auch nicht dessen Bedeutung. Für ihn ist das ein Haufen Pixel und mehr Informationen als die Rohpixel bekommt DQN ja auch nicht.
Auch in Pac-Man spielt DQN unterirdisch. Offenbar kommt er mit Objekten die plötzlich verschwinden oder sich teleportieren um an einer anderen Stelle wieder aufzutauchen nicht wirklich klar.
Dennoch, DeepMinds DQN ist in der Lage schwierige Videospiele zu meistern – obwohl als Input nur die Pixel im Rohformat zur Verfügung stehen. DeepMind hat übrigens den Source-Code ihres DQN für die Öffentlichkeit zugänglich gemacht. Wer mag, kann die Dateien hier runterladen und die schlaue KI selbst auf die Probe stellen. Läuft nur unter Linux.
WER IST DEMIS HASSABIS?
Demis Hassabis ist der Kopf von DeepMind. Sein Lieblingsfilm ist Bladerunner, er liebt Ataris Space Invaders und hat sich mit acht Jahren einen ZX Spectrum von dem Preisgeld gekauft, dass er bei einem Schachturnier gewonnen hatte. Auf dem Specci hat er programmieren gelernt, was ihn fasziniert und geprägt hat.
Kurzum: Demis Hassabis ist mir sympathisch. Aber nicht nur wegen Bladerunner, Space Invaders und Spectrum. Obwohl ich ihn nicht persönlich kenne, sondern lediglich Interviews gelesen habe und Vorträge auf YouTube gesehen habe, bin ich überzeugt davon, dass das Credo von DeepMind: „Die Welt zu einem besseren Ort machen“ für Hassabis keine leere Phrase ist. Das ist sein Antritt. Mir gefällt auch seine bescheidene, zurückhaltende Art.
Videospiele haben Demis Hassabis, Jahrgang 1976, seit seiner Kindheit geprägt. Mit 15 Jahren war er bereits bei Bulfrog. Die Game-Designer Legende Peter Molyneux höchstpersönlich hat Hassabis angeheuert, bevor er die Schule beendet hat. Bei Bulfrog hat er u.a. an Populous II mitgewirkt, und wie sollte es anders sein – die KI programmiert.

Demis seine Spiele sind voller kreativer Ideen und im Kontext der Zeit – mit sehr schlauer KI. Neben Populous II sind dies u.a. Syndicate, Theme Park, Black & White und Republic: The Revolution. Bei Syndicate war er First-level-Designer und bei Theme Park (mit 17 Jahren), Chef-Programmierer.
Hassabis verläst Bulfrog um in Cambridge einen Abschluss in Computer-Wissenschaften zu machen, ebenfalls mit Bestnoten. Nach dem Ende des Studiums arbeitet er wieder mit Peter Molyneux zusammen als Spiele-Entwickler bei Lionhead Studios. Kurze Zeit später gründet er Elixir Studios. Hier entstehen u.a. Republic: The Revolution (2003) und Evil Genius (2004). Doch Hassabis ist in einer Sackgasse: „Ich kann unter dem Deckmantel eines Spiels keine interessante KI-Forschung betreiben.“ Er beschließt, zu promovieren. Am Londoner University College erlangt er 2009 seinen Doktortitel in der Kognitiven Neurowissenschaft Zwei Jahre nach dem Doktor gründet Hassabis mit seinem Studienkollegen Shane Legg und dem Oxford-Abbrecher Mustafa Suleyman das Startup DeepMind Technologies. Vier Jahre später übernimmt die Google-Mutter Alphabet die Firma.
One day I dream of coming back and making the ultimate game with some learning AI in it
Demis Hassabis
Wieso spielt DQN eigentlich so gerne Atari-Klassiker?
Warum lässt DeepMind ihr neurales Netzwerk überhaupt auf Videospiele los? Es steckt natürlich viel mehr dahinter als Spielerei. Tatsächlich geht es darum, dass ihr Programm durch das Navigieren in der virtuellen Welt einen Sinn für die Realität entwickelt. Dafür eigenen sich Videospiele perfekt. Genau wie ein Kind soll die KI spielerisch lernen und sich durch selbstständiges Training verbessern und Wissen aneignen. Es geht darum zu erkunden, zu planen und Entscheidungen zu treffen, in Situationen, die für das Programm neu sind. DeepMind möchte nicht für jede Aufgabe eine eigene KI entwickeln, sondern einen generischen Algorithmus erzeugen, der aus Rohdaten selbständig lernt und die unterschiedlichsten Aufgaben meistert. Videospiele sind ein exzellentes Umfeld, um eine KI zu trainieren, weil sie klar definierte Regeln mit Impulsentscheidungen verbinden, wie es der Forscher Oriol Vinyals von DeepMind ausdrückt. So können die Entwickler mehr über die Stärken und Schwächen der KI herausfinden, Lernprozesse optimieren und die Erkenntnisse dann wieder für andere Anwendungen jenseits von Games nutzen.
Der KI-Forscher Prof. Dr. Christoph Minnameier hat sich die Ergebnisse genauer angesehen und meint: „Tatsächlich könnte die im Prinzip gleiche KI, ausgestattet mit einer Kamera statt einem Bildschirm-Stream und einem Greifarm statt einem Joystick, lernen, Objekte in Kisten zu sortieren. Vorausgesetzt, sie kann das lange genug ausprobieren und bekommt dabei Feedback (in Form von Punkten) für richtige und falsche Handlungen. Diese universelle Lernfähigkeit ist das Alleinstellungsmerkmal von Deep Mind.“
Bei den 2D-Klassikern ist es nicht geblieben. Die Realität ist schließlich Dreidimensional. DQN kommt auch mit 3D zurecht und lernt schnell. Sehr schnell sogar, denn er gewinnt in TORCS (The Open Racing Car Simulator) sicher und unfallfrei jedes Rennen.
In diesem Video zeigt DeepMind wie ihr Agent sich selbst das Laufen beibringt, und sich mehr oder weniger geschickt durch einen Hindernisparcours bewegt. Es ist schon interessant zu beobachten, das der Agent von ganz allein Fortbewegungstechniken wie Springen und Ausweichen entwickeln kann.
Ein wohl noch relevanterer Aspekt ist, dass keines der Spiele eine längerfristige Planung erfordert wie es z.B. bei Schach der Fall ist
Prof. Dr. Christoph Minnameier, 19. August 2015
Keine drei Monate später hat AlphaGo im Paradebeispiel für langfristige Planung – im Spiel Go – das Gegenteil bewiesen.
Minnameier glaubt auch, dass DeepMind weit davon entfernt ist, die ‘gute alte KI’, die speziell für ein Computerspiel programmiert wird, abzulösen. Denn die meisten Spiele erfordern taktisches Verständnis und die Fähigkeit, längerfristig zu planen.
Das dies möglich ist, hat Open AI ja bereits bewiesen, und die weltbesten menschlichen Spieler im Strategiespiel Dota 2 geschlagen. DeepMind möchte da wohl noch einen drauf setzten und hat sich vorgenommen, das gleiche mit Starcraft 2 zu erreichen.
Auch das noch, DeepMind stellt die Schachwelt auf den Kopf
Am 18. Dezember war ich mit dem Zug nach Frankfurt unterwegs und habe mir am Bahnhof eine aktuelle Schachzeitschrift gekauft. Wie es der Zufall so will war ein Artikel über AlphaGo enthalten. Der letzte Satz aus jenem Artikel lautet wie folgt: „Ob es jemals ein erfolgreiches Schach-Gegenstück zum autonom laufenden AlphaGo geben wird? Ich bin skeptisch.“
Die Druckerschwärze dürfte noch nicht getrocknet sein, als AlphaZero – das Schach-Gegenstück zum autonom laufenden AlphaGo – das stärkte Schachprogramm der Welt – Stockfish 8 – mit 28:0 Siegen vernichtend geschlagen hat. Die Nachricht ereilte die Welt am 5. Dezember 2017.
Dieses Ereignis hat die Schachwelt genauso geschockt, wie die Go-Scene die Nachricht über AlphaGo´s Sieg gegen den Go-Weltmeister. Vergleichbar mit dem Sieg von Deep Blue gegen den Schachweltmeister im Jahr 1997.

DEEP BLUE GEGEN GARRY KASPAROV
In 1996 konnte Garry Deep Blue noch mit 4:2 bezwingen. IBM hat dann aber mächtig aufgerüstet und ein Schach-Monster erschaffen, dass 200 (!!) Millionen Stellungen pro Sekunde berechnen kann.
11. Mai 1997:
In einem medialen Großereignis – das alles entscheidenden Match Mensch gegen Maschine – verlor der amtierende Weltmeister in einem auf 6 Partien angelegten Wettkampf unter Turnier-Bedingungen mit 3,5:2,5. Ein Paukenschlag!
Ein Computer schlägt den amtierenden Weltmeister auf einem Gebiet, auf dem Phantasie, Einfallsreichtum, Intuition, Kreativität – ja Intelligenz gefragt sind. Eigenschaften, von denen wir Menschen uns ja gerade von den Computern zu unterscheiden glaubten. Aber mit Intelligenz hatte Deep Blue nichts zu tun. Eher schon mit roher Gewalt. Denn die Maschine war auf pure Rechenkraft konzipiert worden und setzte die Brute Force-Methode ein. Eine Strategie, in der der Variantenbaum stumpf aber präzise bis zu einer definierten Tiefe vollständig analysiert wird, um den besten Zug zu finden.
Dieses Ereignis hat die Überlegenheit der Schachcomputer eingeläutet und hatte gleichzeitig eine spürbare psychologische Wirkung gehabt. Besonders auf Kasparov selbst, der sich erst 20 Jahre später hiervon erholen sollte. Seitdem wurden die Programme ständig weiter verfeinert. Stockfish, Komodo und Houdini stellen nun Sperrspitze dar und Stockfish ist der König unter ihnen. Brute Force ist Alpha-Beta gewichen, aber Intelligent sind die Programme weiterhin nicht. Aber dennoch teuflisch gut im Schach.
Auch wenn weitere Weltmeister und Weltklassespieler – u.a. Kramnik gegen Deep Fritz 10, Adams gegen Hydra und zuletzt Nakamura gegen Stockfish und Komodo (mit Bauernvorgabe) – die Ehre der Menschheit zu retten versuchten; sie sind alle gescheitert und konnten nicht eine einzige Partie für sich entscheiden.
Nun könnte man meinen, dass nach dem Erfolg von IBM´s Deep Blue gegen den 13. Schachweltmeister Garry Kasparov im Jahr 1997 die Sache Mensch gegen (Schach)Maschine ja längst gegessen sei.
Dem ist auch so; seitdem haben sich die Schach-Engines stets verbessert und sind für Menschen schon lange unbezwingbar. Selbst die Stockfish-App auf dem Handy schlägt jeden Großmeister mühelos. Und gerade deshalb war diese Nachricht für die Schachprofis so schockierend. Für die Profis ist Stockfish ein unverzichtbarer Helfer. Die Weltspitze nutzt es ehrfürchtig zur Analyse, zum Training und zur Turniervorbereitung.
Was Stockfish ausspuckt, ist Gesetz. Das galt bis zum bis zum 5. Dezember 2017. Um den Stärkeunterschied zwischen Mensch und Maschine greifbar mal zu machen: Die aktuelle Version von Stockfish erreicht eine Elo von ~ 3.450 Punkten, dicht gefolgt von Houdini und Komodo. Der beste Mensch, Magnus Carlsen, der amtierende Weltmeister und Weltranglistenerste kommt auf eine Elo-Wertung von aktuell ~ 2.840 Punkten. Dazwischen liegen Welten. Schon bei 100 Elo-Punkten Unterschied errechnet sich eine erwartete Punkteausbeute von 64%.
ELO – WIE DIE SPIELSTÄRKE IM SCHACH GEMESSEN WIRD
Im Schach ist die Spielstärke durch verschiedene Wertungssysteme messbar. Das bekannteste und bestorganisierteste ist das von Arpad Elo eingeführte ELO-System. Es erlaubt die Ermittlung der zu erwartenden langfristigen Punkteausbeute für beliebige ELO-Differenzen zwischen den beteiligten Spielern. Es ist so kalibriert, dass eine ELO-Differenz von 100 Punkten eine langfristige Punkteverteilung von 64% zu 36% erwarten lässt. Bei 400 Punkten wird dies zu 92% zu 8% und bei 500 Punkten kann der Schwächere nur eine Punkteausbeute von 4% erwarten (Sieg = 1, Remis =0,5 und Niederlage = 0 Punkte).
Aus dem Buch „Expeditionen in die Schachwelt: Helden, Taten, Denkanstöße“ von Christian Hesse
Und plötzlich kommt aus heiterem Himmel ein Programm, das sich in nur vier Stunden durch selbstständiges Spielen gegen sich selbst Schach beibringt, um anschließend mit Stockfish mal eben den Boden aufzuwischen.
DeepMind hat von den 100 gespielten Partien lediglich 10 Partien veröffentlicht. Ganz sicher, die meist analysierten Partien des Jahres.
Nach Maschine sehen die Partien von AlphaZero überhaupt nicht aus. Eher schon wie die Partien des legendären Paul Morphy (1837-1884). Damals gab es noch keine Schachcomputer und die Spielweise war viel risikofreudiger. Material war nicht so entscheidend, schon gar nicht für Morphy. Er war mit seinem Schachverständnis seiner Zeit weit voraus. Seit Computer in die Schachwelt eingezogen sind, spielen die Profis risikoärmer, defensiver, opfern selten Material. Ein einziger Bauer mehr auf dem Brett entscheidet meist die Partie.
Das könnte sich durch AlphaZero ändern. Die Art und Weise wie AlphaZero spielt ist verblüffend. AlphaZero spielt von Beginn an sehr aggressiv, angriffslustig, hat stets die Initiative und schert sich nicht um Material. Opfert Bauern und Figuren ohne einen unmittelbaren offensichtlichen Vorteil daraus zu ziehen. Sehr ungewöhnlich.
Wenn herkömmliche Schachprogramme gegeneinander spielen, gehen sie meist Remis aus. „In der Tat unterscheiden sich die Partien deutlich von normalen Computerpartien, in denen in der Regel 150 bis 170 Züge herummanövriert wird. AlphaZero spielte mutiger“, so GM Ian Nepomniachtchi.
Die Partien können auf Chess24.com mit der Bewertungsfunktion von Stockfish 8 nachgespielt werden. Das bedeutet, die Stockfish- Engine läuft im Hintergrund mit und man kann in Bauerneinheiten ablesen, wie es die Stellung einschätzt.
Die Partien wirken so, als würde Stockfish unter einer vernebelten Dunstglocke spielen, während AlphaZero bei völlig klarer Sicht von oben auf das Brett schaut und sogar hindurch. Während SF die Stellung für ausgeglichen hält und glaubt alles sei in Ordnung, weiß AlphaZero offenbar dass das Spiel schon längst entschieden ist. Gerne hätte ich auch die Einschätzung von AlphaZero dazu gesehen.
In sieben von 10 Partien hat AlphaZero Material geopfert, um positionellen Vorteil zu erlangen. In einer Partie liegt er bereits mit einem Bauern hinten und stellt dann einen Springer ein, nur um seinen Turm zu entwickeln. In eine andere Partie hatte sich Stockfish eine starke Verteidigungsposition aufgebaut, mit klarem materiellem Vorteil. AlphaZero schien durchzudrehen, und schickte seinen Läufer quer über das Brett mitten ins Feindgebiet, auf ein Feld, dass durch einen Bauern geschlagen werden kann. Aber dann passierte etwas Unerwartetes. Alle weißen Figuren wurden auf einen Schlag aktiv, während die Schwarzen wie ein hilfloser verknoteter Haufen zurückblieben. Ein Zug, auf den die besten Schachprogramme selbst mit stundenlanger Bedenkzeit nicht gekommen sind. AlphaZero hat ihn in einer Minute gefunden. Züge, die aussehen wie Anfängerfehler, entpuppen sich als brillant.
In der 3. Partei passiert etwas noch erstaunlicheres. AlphaZero bringt seinen Gegner in Zugzwang. Das ist überaus selten im Schach, schon gar nicht gegen so einen übermächtigen Gegner. Die berühmteste Zugzwang-Partie hat Aaron Nimzowitsch gegen Friedrich Sämisch 1923 in Kopenhagen gespielt.
Erstaunlich ist, das Stockfish offensichtlich keinen Schimmer hat, was um ihn herum geschieht …
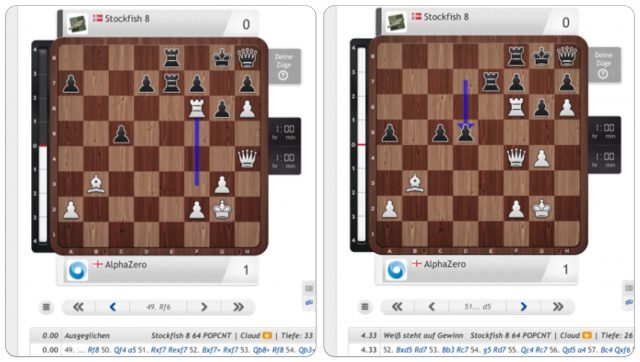
Mit einer Qualität und zwei Bauern weniger auf dem Brett ist AlphaZero materiell völlig unterlegen. Stockfish hat die Stellung bis zum 49. Zug als völlig ausgeglichen bewertet, war aber trotz materieller Überlegenheit völlig hilflos. Alle Figuren standen passiv; jeder Zug hätte seine Situation nur noch verschlimmert. Beide Türme und die Dame können nicht ziehen, ohne sofort zu verlieren. Im Schach nennt man das Zugzwang. Man könnte auch von Dominanz sprechen. AlphaZero hatte Brett und Gegner völlig unter Kontrolle. Nur zwei Züge später schlug die Bewertung von „Ausgeglichen“ auf „Weiß steht auf Gewinn“ um; wenig später gab Stockfish auf. So eine Partie gegen das Schach-Monster Stockfish zu sehen, Wow. Unglaublich, wenn man bedenkt wie bockstark Stockfish ist. Die anderen Partien sind ähnlich spektakulär. Hier sind zwei Welten aufeinander geprallt, mit völlig konträreren Ansätzen.
„Ich habe mich immer gefragt, was passiert, wenn höhere Wesen auf der Erde landen und uns zeigen, wie sie Schach spielen. Jetzt weiß ich es“, sagte Magnus‘ Carlsens Sekundant GM Peter Heine-Nielsen, nachdem er die zehn Partien gesehen hatte.
Nicht nur Heine-Nielsen ist Baff: Viele Spitzenspieler zeigten sich ebenfalls stark beeindruckt.
GM Jon Ludvig Hammer: „Wir alle wussten, dass Computer taktische Monster sind – mich haben die positionellen Siege beeindruckt. Die Partien 7 bis 9 sind genial!““
GM Wesley So: Ich war schockiert. Das ist eine große Sache. Es verändert das Schach völlig. Wie stark ist das Programm? 3700? Fast 4000? Das ist wirklich verrückt.“
FIDE Meister Mile Klein: „Das wäre vergleichbar mit einem Roboter, der Zugang zu Tausenden von Metallteilen und -teilchen erhält, aber keine Kenntnis von einem Verbrennungsmotor hat und dann so lange mit jeder möglichen Kombination experimentiert, bis er einen Ferrari gebaut hat.“
Sehr ungewöhnlich ist auch die Ausbeute mit Weiß. Von den 28 gewonnenen Partien gegen Stockfish gewann AlphaZero 25 Partien mit den weißen Steinen, aber nur drei Partien mit den schwarzen. Üblicherweise beträgt der statistische Unterschied zwischen Weiß und Schwarz im Schach 55%. Garry Kasparov glaubt, dass der Anzugsvorteil von Weiß wohl neu beurteilt werden muss.
„Ein Schachcomputer kann keine Straße überqueren“. So lautet der Titel eines Artikels der Süddeutschen Zeitung vom 11. März 2016 über Künstliche Intelligenz. Das suggeriert schon in der Überschrift, dass KI nicht mehr kann als Schachspielen und in der realen Welt keine vernünftigen Anwendungen findet.
Der Satz lautet übrigens vollständig: „Ein Schachcomputer jedoch kann die Straße nicht überqueren, er kann noch nicht einmal Go spielen.“ Offenbar ist den Redakteuren dabei entgangen, dass Google´s AlphaZero genau dies kann. Schach, Go, Shogi und noch viel mehr. Die Medien vergleichen den Erfolg von AlphaZero wohl mit dem von IBM Deep Blue aus 1997. Nur das es da einen gravierenden Unterschied gibt.
Der Unterschied zwischen AlphaZero und Deep Blue besteht darin, dass Deep Blue direkt mit Wissen über Schach gefüttert wurde, während AlphaZero mit der Fähigkeit programmiert wurde, dieses Wissen selbständig zu erlernen.
Dieser feine Unterschied scheint vielen Medien entgangen zu sein. Vermutlich weil Computer schon lange besser als Menschen Schach spielen können und Go hierzulande kaum jemanden interessiert. Die eigentliche Sensation – ein selbstlernendes neurales Netzwerk – wird dabei kaum wahrgenommen. Das ist in gewisser Weise auch verständlich, da es so unglaublich ist.
„Wenn Sie Angst vor dem Terminator haben, machen Sie einfach die Tür zu.“ So lautet eine weitere Schlagzeile aus eben jenem Artikel. Der Satz stammt von Oren Etzioni, Leiter des Allen Institute for Artificial Intelligence in Seattle. Etzioni weiter: „Roboter haben gewaltige Probleme damit, Türen zu öffnen. Also: Wenn Sie sich vor so einer Maschine fürchten, dann schließen Sie daheim alle Türen.“
Mag sein, das KI meist auf geschlossene System beschränkt ist; weit davon entfernt ist, sich im Straßenverkehr zurechtzufinden – von den Fähigkeiten eines menschlichen Gehirns ganz zu schweigen. Aber was geschlossene Türen betrifft, bin ich nicht so sicher wie Oren Etzioni …
Der gelbe SpotMini von Boston Dynamics kann dank eines Greifarms die Klinke herunter drücken und die Tür öffnen. Im Video hilft er dabei einem armlosen Artgenossen. Boston Dynamics ist lt. Wikipedia ein Robotik-Unternehmen mit Sitz in Waltham (Massachusetts), das vor allem im Bereich autonomer Laufroboter forscht. Es gilt als eines der am weitesten fortgeschrittenen Robotik-Unternehmen der Welt. Boston Dynamics hat zu Beginn noch für das US-amerikanische Militär entwickelt. Ende 2013 wurde die Firma von Google aufgekauft. Wie DeepMind ein Jahr später auch.
Faszinierend und beängstigend zugleich
Ich finde die Fortschritte, die DeepMind in so kurzer Zeit erreicht hat, sehr beeindruckend. Es ist nicht so, dass DeepMind neue Erkenntnisse; neue Theoreme oder völlig neue Ansätze geschaffen hätte.
Denn die Entdeckung neuraler Netze und dessen Erforschung gehen bereits auf die 50er Jahre zurück. Und auch Q-Learning sowie die zufallsbasierte Suchmethode Monte Carlo Tree Search (MTCS) sind nicht neu. Der Einsatz Letzteres hat übrigens dazu geführt, dass Go-Programme vor zehn Jahren einen großen Schritt nach vorne gemacht haben. Andrey Kurenkov gibt auf seinem Blog einen hervorragenden Überblick über die Geschichte der KI.
Offenbar ist es DeepMind aber gelungen, bekanntes Wissen aus jahrzehntelanger Forschung brillant zu kombinieren.
Andererseits sind die Fortschritte von DeepMind auch beängstigend. Bisher ist die KI von DeepMind auf geschlossene Systeme beschränkt. Aber wie lange noch? Und wie entwickelt sich das weiter? Wenn ein neurales Netz in der Lage ist, selbstständig unentwegt zu lernen und sich dadurch ständig verbessert, schlauer wird, dann hat es ja auch keine Beschränkungen mehr. Wie beim Schach und Go schafft es Wissen aus dem Nichts, das uns Menschen bisher verborgen blieb und womöglich übertrifft.
Die Kernfrage lautet: Wie Anpassungsfähig wird es sein? Und wie schnell gelingt ihm das. Ist ein solch mächtiger Algorithmus in den Händen der Datenkrake Google gut aufgehoben? Was würde die NSA damit anstellen, die ja auch nicht davor zurückschreckt „Freunde“ auszuspähen? Experten fürchten sich auch vor automatisierten Entscheidungen, die im Nachhinein niemand erklären und künftig verhindern kann. Das reicht von simplen automatisierten Kreditentscheidungen über eine PKW-Finanzierung bis hin zu Drohnen, die autonom töten können. Ähnlich wie WOPR im Film War Games. Neurale Netze sind ab einer bestimmten Ebene selbst für ihre Schöpfer undurchschaubar; deren Entscheidungen nicht mehr nachvollziehbar. Den Code will DeepMind unter Verschluss halten. AlphaZero soll eine Blackbox bleiben, wie es viele andere Systeme mit KI auch sind.
Der berühmte Physiker Stephen Hawking und der Tesla-Gründer Elon Musk, warnen vor dieser Art von KI, obwohl Musk selbst Investor von DeepMind ist. „Computer können theoretisch menschliche Intelligenz nachahmen und diese auch übertreffen“, so Hawking. „Wenn wir erfolgreich KI erzeugen können, wäre das das wichtigste Ereignis unserer Geschichte. Oder das schlimmste.“ Musk wiederum glaubt, KI sei bedrohlicher als Atomwaffen.
Die Frage ist immer: Wie geht die Gesellschaft mit neuer Technologie um? Man kann KI dazu einsetzen, neue Krebsbehandlungen zu finden, oder autonome Waffen zu bauen. Das hängt von uns ab, so Geoff Hinton, Forscher im Bereich künstlicher neuronaler Netze.
Muss man also diese KI kontrollieren, wie Atomwaffen? Und wenn ja wie?
Forscher von OpenAI, einem industrienahen Non-Profit-Unternehmen, formulieren die Situation so: „Fortschrittliche KI entwickeln und sie erst später sicher machen, ist wie das Internet aufbauen und anschließend versuchen, es sicher zu machen.„
Aber diese Technik ist wiederum auch so faszinierend, so spannend, mit so unglaublich vielen (sinnvollen) Anwendungsmöglichkeiten und überraschenden Resultaten. Nicht nur Roboter werden sich verändern. Wird es diese Art von KI auch bald in Videospielen geben? Oder wird ein Go-/Schachprogramm für „normale“ PCs erhältlich sein?
Vorerst eher nicht. Denn DeepMind hat eigene, sehr besondere Hardware verwendet. Mächtige Hardware. So hat sich AlphaZero zwar in „nur“ vier Stunden selbst Schach beigebracht, hat aber in dieser Zeit 44 (!!!) Millionen Partien gegen sich selbst gespielt. AlphaZero nutze für das Training 5.000 sog. „first-generation“ TPUs (Tensor Processing Unit) aus dem Google Hardware-Park. Diese TPUs besitzen lt. Wikipedia eine Rechenleistung von 180 TFLOPS und werden zu einem „Pod“ mit 11,5 PFLOPS zusammengeschaltet. Die TPU´s sind natürlich nicht im Handel erhältlich und wären wohl auch nicht bezahlbar. Abhilfe könnte aber – wie könnte es anders sein – die Videospielindustrie schaffen:
Aber vor allem verdankt das Deep Learning auch der Spiele-Industrie eine Menge. Irgendwann gingen Forscher daran, die Grafikkarten, die eigentlich für Computerspiele entwickelt worden waren, als kleine Superrechner zweckzuentfremden. Plötzlich hatten wir dank der Grafikkarten von Firmen wie Nvidia genug Rechenpower für unsere künstlichen neuronalen Netze.
Geoff Hinton, 68, ist Informatiker an der kanadischen University of Toronto und einer der wichtigsten Forscher im Bereich künstlicher neuronaler Netze.
Die benötigte Rechenleistung wäre wohl möglich; Nvidia sei Dank. Aber abgesehen davon, dass DeepMind ihre Codes unter Verschluss hält, gibt es da noch ein weiteres Problem: Speicher.
Das neurales Netz ist das Gedächtnis der KI und das muss ziemlich groß sein. DeepMind hat dafür die Google-Clouds genutzt. Man kann sich vorstellen, dass allein die 44 Millionen Schachpartien die AlphaZero während des vierstündigen Trainings gespielt hat, einen enormen Speicherbedarf benötigen. Das Netzwerk speichert ja nicht nur die Partien, sondern auch die Stellungen die sich daraus ergeben können und justiert es damit. Sowohl die Großmeister im Schach als auch im Go waren der Auffassung, dass AlphaZero nicht allein mit schierer Rechenleistung gewonnen hat, sondern mit Intuition. Das stimmt in gewisser Weise auch.
Für Intuition ist Erfahrung zwingend erforderlich. Und Erfahrung erlangt man durch ausgiebiges Training und der Feinjustierung des neuralen Netzes. Ein „ausgelerntes“ Schach- oder Go-Programm mit den im neuralen Netz gespeicherten Erfahrungen braucht sicher viel Speicherplatz. Aber auch das sollte in Zeiten von Clouds und der fortschreitenden Entwicklung von Speichermedien kein Hindernis sein. 1983 waren die 64 KB RAM des C64 schon richtig viel, 64 mal so viel wie der Speicher des ZX81.
Aber DeepMind hat höhere Ziele und möchte sich künftig auf allgemeinere Algorithmen konzentrieren, die der Menschheit helfen sollen. Dazu gehörten Arzneien für Krankheiten, die Senkung des Energieverbrauchs oder das Erfinden neuer Materialien.
Naja, so ganz kann DeepMind nicht die Finger von Videospielen lassen. Denn aktuell lernt die KI Blizzard´s Starcraft II. Eine große Heraufforderung, so DeepMind-Mitarbeiter Oriol Vinyals. Viele Faktoren erschweren die Programmierung einer Starcraft-KI. So sieht man beispielsweise nicht die gesamte Karte, sondern muss sie erst erforschen („Fog of War“). Ein Spiel kann ein paar Minuten bis zu einer Stunde dauern. Aktionen, die früh im Spiel ausgeführt werden, zahlen sich möglicherweise für eine lange Zeit nicht aus. Schwer zu greifen für das Belohnungssystem. Strategien sind also ziemlich kompliziert und müssen langfristig geplant sein. Um nur eine bestimmte Einheit zu bauen, muss man erst Rohstoffe sammeln und verschiedene Gebäude errichten. Dazu kommen drei unterschiedliche Rassen, die jeweils eigene Stärken und Schwächen haben. Aber wem sage ich das.
SO TRAINIERT DFQN FÜR STARCRAFT II
DeepMind kooperiert mit Blizzard. Über eine Schnittstelle erhalten Programmierer ein Interface, über das sie DQN an das Spiel „andocken“. Die Veröffentlichung enthält auch eine Reihe von „Minispielen“ um das Spiel in handhabbare Brocken zu zerlegen. DQN lernt Aufgaben wie das Sammeln von Rohstoffen, die Erstellung von Marines oder das Gruppieren von Einheiten. Das folgende von DeepMind veröffentlichte Video zeigt DQN beim Training.
Die Starcraft-Profis sehen DeepMinds spielenden Agenten übrigens gelassen entgegen. Byun Hyun-woo, der amtierende Weltmeister aus Südkorea sagte: „Ich werde es nicht mehr erleben, dass eine KI-Software einen menschlichen Profi in Starcraft 2 schlagen werde“.
Aber das hatten die Go-Profis bis letztes Jahr ja auch von ihrem Spiel behauptet.
Es bleibt also spannend!
ENDE
FILMTIP ALPHAGO THE MOVIE
AlphaGo The Movie ist eine überraschend berührende Dokumentation über die Duelle, die AlphaGo gegen den Europameister Fan Hui und den Go-Weltmeister Lee Sedol geführt hat. Auch ohne Go-Kenntnisse ein sehenswerter Film. Er beginnt mit einer eMail: CEO Demis Hassabis lädt Fan Hui zu einem Experiment ein. Fan Hui nimmt an, ohne zu wissen, was ihn erwartet. Er verliert zwar gegen AlphaGo, gewinnt aber dafür die Sympathien der Zuschauer, findet eine Schwäche in AlphaGo und hilft anschließend DeepMind ihr Programm zu verbessern. Dann geht´s nach Seoul. Showdown. Knisternde Spannung. Mega-Ereignis. 280 Millionen TV-Zuschauer live weltweit. Nervosität bei DeepMind und Zuversicht bei Lee Sedol. Für Sedol ist es das Spiel seines Lebens.
Vor dem Match sagte Sedol, er spiele nicht für sich, nicht für sein Land, sondern für die Menschheit. Sehr berührend, die emotionale Entwicklung von Sedol hautnah mit zu verfolgen. Sein Stolz, der Schock nach der ersten verlorenen Partie, seine Zerbrechlichkeit, seine Fassungslosigkeit und seine Enttäuschung. Und die unglaubliche Erleichterung, wenigsten eine Partie gewonnen zu haben. Unbändige Freude im ganzen Land; auch ich habe mich für ihn gefreut. Der wichtigste Sieg seines Lebens, wie er später sagt. Aber auch hinter den Kulissen ist die Spannung und Anspannung greifbar: Kurz vor der ersten Partie findet das AlphaGo-Team einen schweren Bug; keine Zeit ihn zu fixen; zu riskant jetzt noch Eingriffe vorzunehmen. Dann, erstaunte Programmierer während der 4. Partie; etwas läuft schief… Ich habe keine Ahnung von Go, fand aber keine Minute langweilig. Am Ende gibt es nur Gewinner.
https://www.youtube.com/watch?v=l9sztL9FQto
Quellenangaben und weiterführende Links
- DeepMind Homepage
- Veröffentlichung in der Nature über DQN spielt Atari-Klassiker „Human-level control through deep reinforcement learning“
- Veröffentlichung von DeepMind DQN spielt 49 klassische Videospiele „Playing Atari with Deep Reinforcement Learning“
- Demis Hassibis und seine Spiele
- Vortrag von Demis Hassabis über KI, Atari, Go usw.
- Artikel der pcgames über Demis Hassibis Spiele: “A conversation with Demis Hassabis, the Bullfrog AI prodigy now finding solutions to the world’s big problems”
- Artikel aus heise.de: „DeepMind: Nach Go lernt Googles KI Starcraft II“
- Trailer AlphaGo The Movie – Eine sehenswerte Dokumentation! Läuft derzeit auf Netflix.


{kind=link}
Schreibe einen Kommentar